|
Welcome! I am a Research Scientist at ByteDance Seed Edge.
I am a core contributor to BAGEL
Email / Google Scholar / GitHub / Linkedin |

|


|
|

|
Deyao Zhu*, Xin Zhou*, Shengling Qin*, Xuekai Zhu*, Hangliang Ding*, Shu Zhong*, Zixin Wen*, et al. Preprint, 2026 arXiv / code / dataset / website EdgeBench studies how agents learn from real-world environments across 134 long-horizon tasks, revealing log-sigmoid scaling laws from large-scale environment interaction. |

|
Chaorui Deng*, Deyao Zhu*, Kunchang Li*, Chenhui Gou*, Feng Li*, Zeyu Wang*, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, Haoqi Fan Preprint, 2025 arXiv / code / model / website BAGEL is an open-source unified multimodal model for understanding and generation, pretrained on large-scale interleaved text, image, video, and web data. |
|
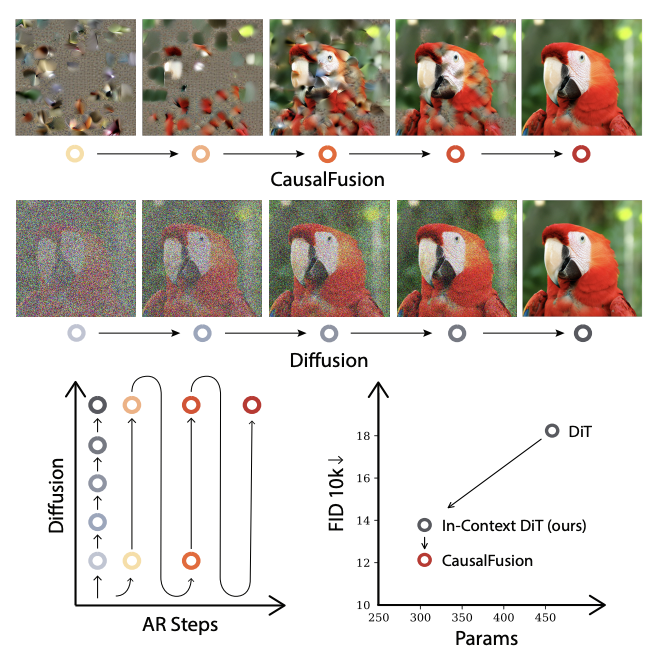
Chaorui Deng, Deyao Zhu, Kunchang Li, Guang Shi, Haoqi Fan Preprint, 2024 arXiv Causal Diffusion introduces a next-token forecasting view of diffusion models and proposes CausalFusion, a decoder-only transformer that factorizes data across sequence positions and diffusion noise levels. |
|
Deyao Zhu*, Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny ICLR, 2024 arXiv / code / model / dataset / website / demo / video MiniGPT-4 shows that the secret behind the next-level vision-language-ability of GPT-4 can be simply a more powerful LLM. By aligning open-sourced vision and advanced language models together, MiniGPT-4 reproduces many GPT-4's vision-related demo. |

|
Deyao Zhu, Jun Chen, Kilichbek Haydarov, Xiaoqian Shen, Wenxuan Zhang, Mohamed Elhoseiny TMLR arXiv / code We discover the powerful questioning ability of modern LLMs. We use it to enrich the image caption of BLIP-2 by prompting ChatGPT to keep asking informative questions to BLIP-2 and summarize the conversation at the end as the final caption. |
|
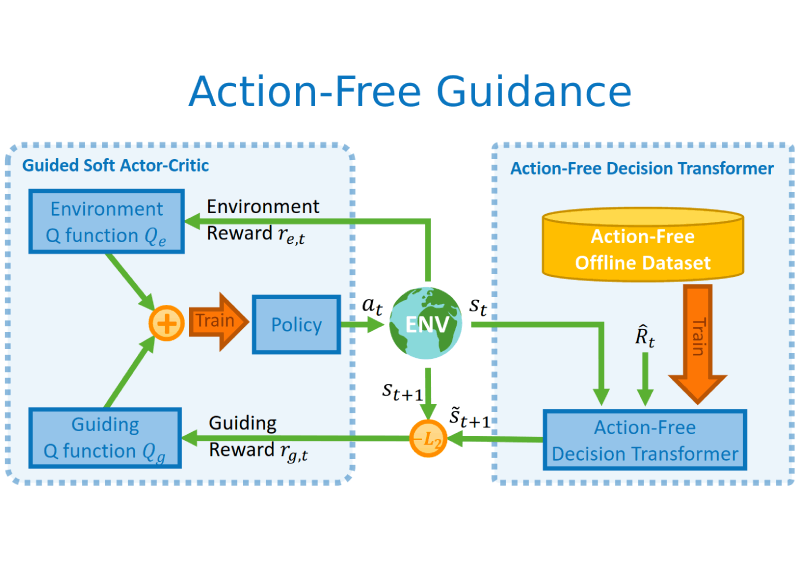
Deyao Zhu, Yuhui Wang, Jürgen Schmidhuber, Mohamed Elhoseiny Preprint arXiv / code Extract knowledge from datasets without action labels to help online reinforcement learning by pretraining an Action-Free Decision Transformer to form intrinsic rewards. |
|
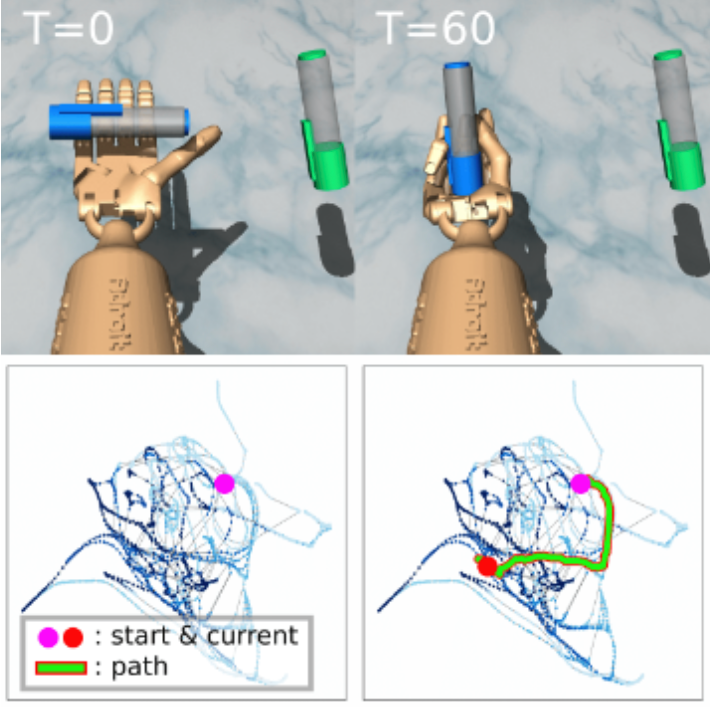
Deyao Zhu, Li Erran Li, Mohamed Elhoseiny ICLR, 2023 openreview / arXiv / code Applying RL methods on a graph world model instead of the original complex environment simplifies the policy learning. |
|
Abduallah Mohamed, Deyao Zhu, Warren Vu, Mohamed Elhoseiny Christian Claudel, ECCV, 2022 arXiv / code / demo A better metric for trajectory prediction that consider the whole prediction distribution. |
|
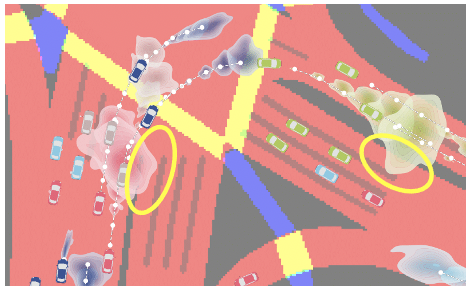
Deyao Zhu, Mohamed Zahran, Li Erran Li, Mohamed Elhoseiny CoRL, 2021 (Oral Presentation) openreview / code Reducing the likelihood of the context-violating predictions directly in the predicted distribution improves the prediction quality. |
|
|
| Third-Place in Habitat Rearrangement Challenge 2022 |
| Reviewer in TPAMI, CoRL 2022, ECCV 2022, AAAI 2023, CVPR 2023 |
| Teaching Assistant in CS283 Deep Generative Model and CS326 Low Resource Deep Learning |
|
|