|
Welcome! I am a PhD candidate at KAUST, where I work on Multimodal Large Language Model, Prediction Model, and Reinforcement Learning advised by Mohamed Elhoseiny. I'm a Hokkien Chinese from Quanzhou. Email / CV / Google Scholar / GitHub / Linkedin |

|
|
My research interests lie in AGI. In particular, I am interested in designing multimodal language models that can make decision. This includes Reinforcement Learning, Video & Language Understanding, Planning via Large Language Model, Motion Forecasting, and other related deep learning topics. |
|
Deyao Zhu*, Jun Chen*, Xiaoqian Shen, Xiang Li, Mohamed Elhoseiny Preprint arXiv / code / model / dataset / website / demo / video MiniGPT-4 shows that the secret behind the next-level vision-language-ability of GPT-4 can be simply a more powerful LLM. By aligning open-sourced vision and advanced language models together, MiniGPT-4 reproduces many GPT-4's vision-related demo. |
|
Jun Chen, Deyao Zhu, Kilichbek Haydarov, Xiang Li, Mohamed Elhoseiny Preprint arXiv / code Video ChatCaptioner creates comprehensive spatiotemporal video descriptions by letting ChatGPT to select the video frame it want to know and ask questions to BLIP-2. ChatGPT at the end summarizes all the information from BLIP-2 as the final video description. |

|
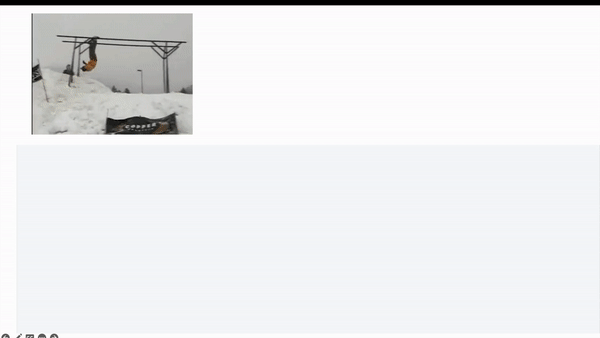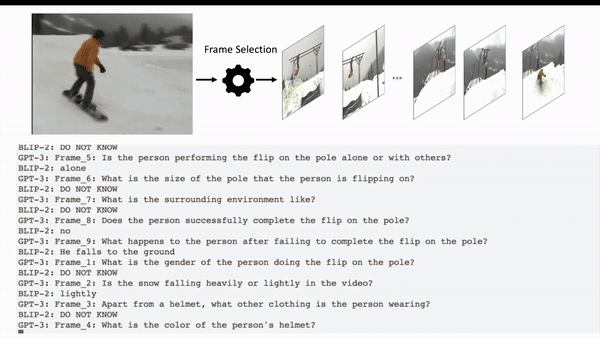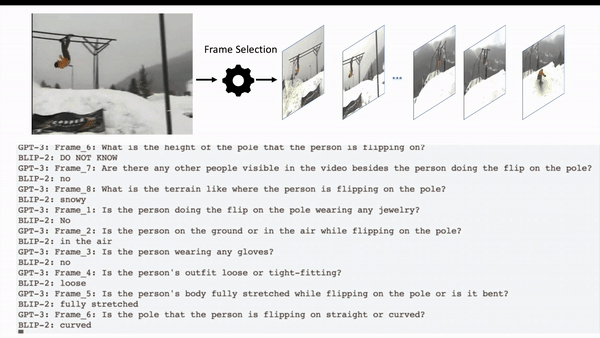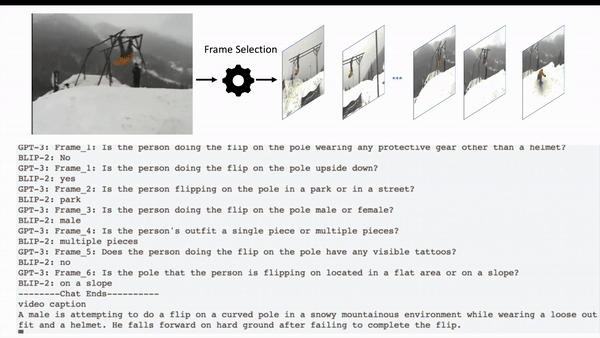
Deyao Zhu, Jun Chen, Kilichbek Haydarov, Xiaoqian Shen, Wenxuan Zhang, Mohamed Elhoseiny Preprint arXiv / code We discover the powerful questioning ability of modern LLMs. We use it to enrich the image caption of BLIP-2 by prompting ChatGPT to keep asking informative questions to BLIP-2 and summarize the conversation at the end as the final caption. |
|
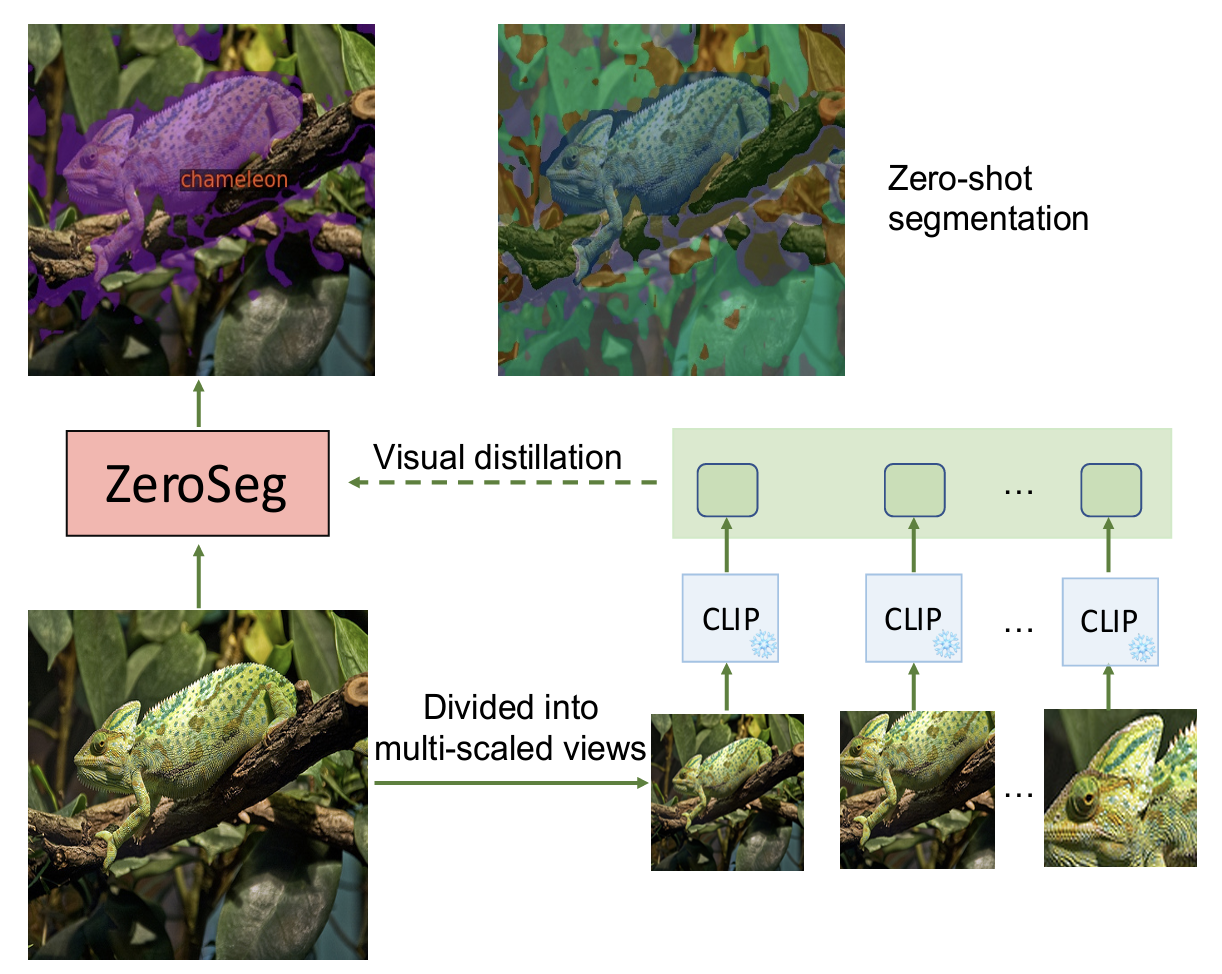
Jun Chen, Deyao Zhu, Guochen Qian, Bernard Ghanem, Zhicheng Yan, Chenchen Zhu, Fanyi Xiao, Mohamed Elhoseiny, Sean Chang Culatana Preprint arXiv ZeroSeg,a novel method that leverages the existing pretrained vision-language(VL) model to train open-vocabulary zero-shot semantic segmentation models |
|
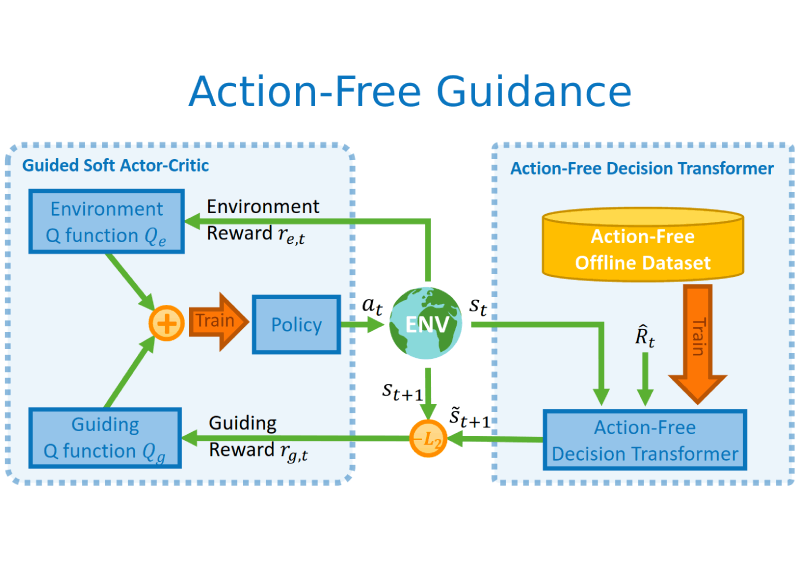
Deyao Zhu, Yuhui Wang, Jürgen Schmidhuber, Mohamed Elhoseiny Preprint arXiv / code Extract knowledge from datasets without action labels to help online reinforcement learning by pretraining an Action-Free Decision Transformer to form intrinsic rewards. |
|
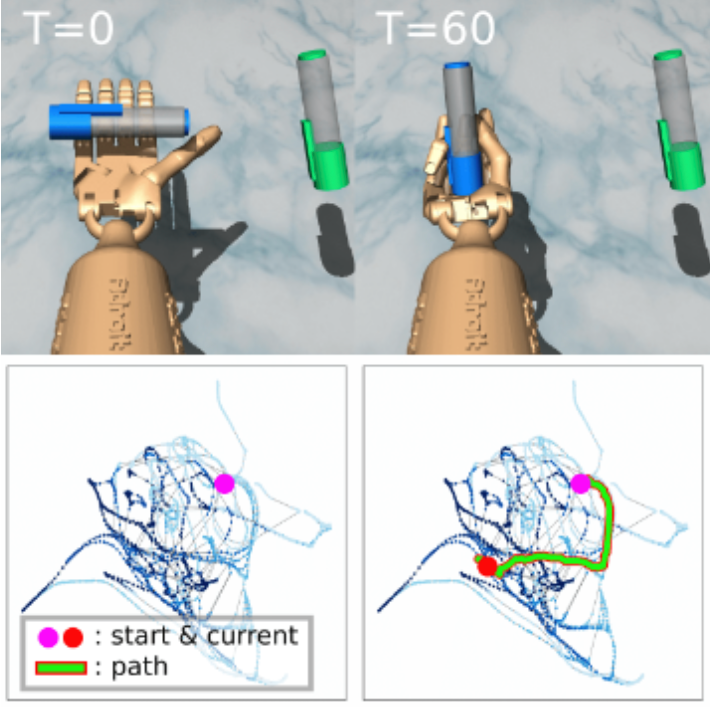
Deyao Zhu, Li Erran Li, Mohamed Elhoseiny ICLR, 2023 openreview / arXiv / code Applying RL methods on a graph world model instead of the original complex environment simplifies the policy learning. |
|
Abduallah Mohamed, Deyao Zhu, Warren Vu, Mohamed Elhoseiny Christian Claudel, ECCV, 2022 arXiv / code / demo A better metric for trajectory prediction that consider the whole prediction distribution. |

|
Jun Chen, Aniket Agarwal, Sherif Abdelkarim, Deyao Zhu, Mohamed Elhoseiny CVPR, 2022 arXiv/ code Modeling an effective message-passing flow through an attention mechanism can be critical to tackling the compositionality and long-tail challenges in visual relationship recognition. |
|
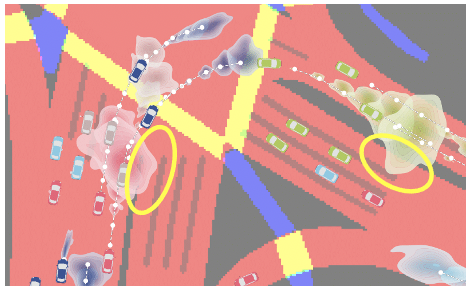
Deyao Zhu, Mohamed Zahran, Li Erran Li, Mohamed Elhoseiny CoRL, 2021 (Oral Presentation) openreview / code Reducing the likelihood of the context-violating predictions directly in the predicted distribution improves the prediction quality. |
|
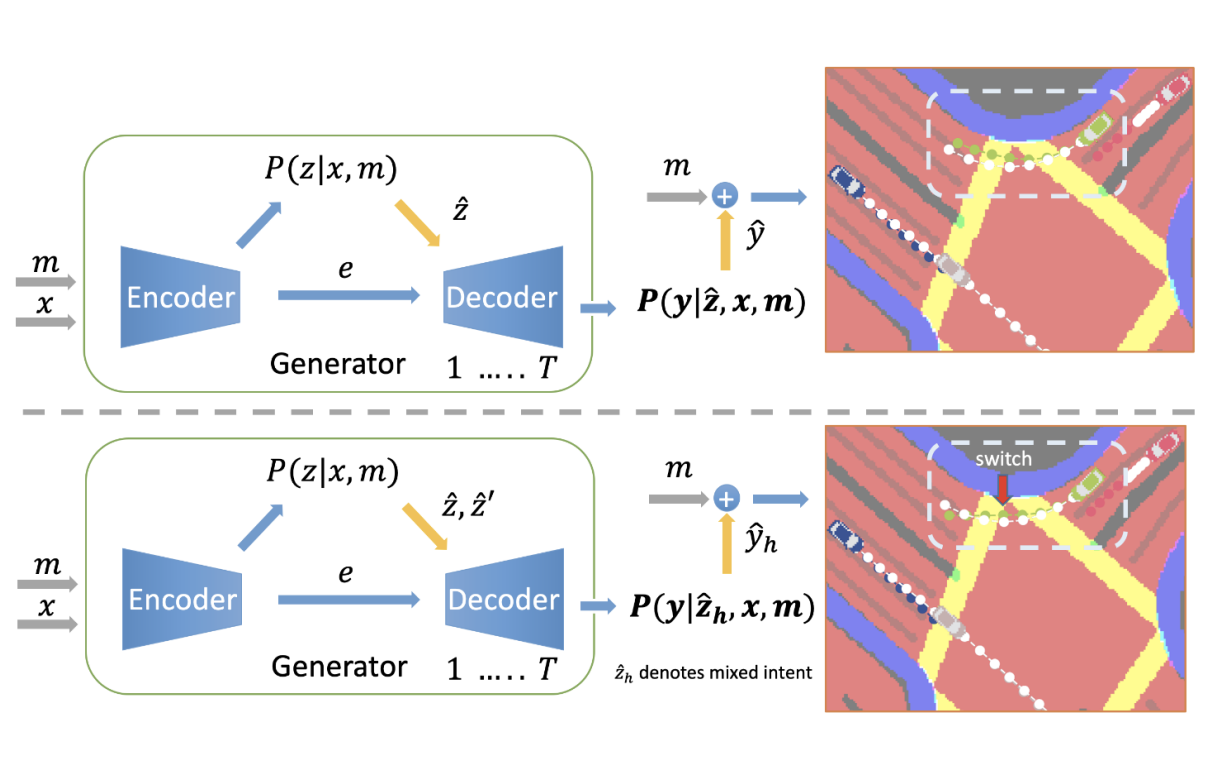
Deyao Zhu, Mohamed Zahran, Li Erran Li, Mohamed Elhoseiny ICLR, 2021 openreview / video Hallucinating surrounding vehicles' driving intents helps model predict better. |

|
Deyao Zhu, Marco Munderloh, Bodo Rosenhahn, Jörg Stückler GCPR, 2019 openreview / code / video Reducing the total correlation of the latent feature's dimensions to learn a physically disentangled representation of blocks. |
|
|
| Third-Place in Habitat Rearrangement Challenge 2022 |
| Reviewer in TPAMI, CoRL 2022, ECCV 2022, AAAI 2023, CVPR 2023 |
| Teaching Assistant in CS283 Deep Generative Model and CS326 Low Resource Deep Learning |
|
|